Data can play an important role for social sector organisations by helping them track progress, measure impact, and identify areas for improvement. It can also help social sector organisations communicate their work to funders, partners, and the general public.
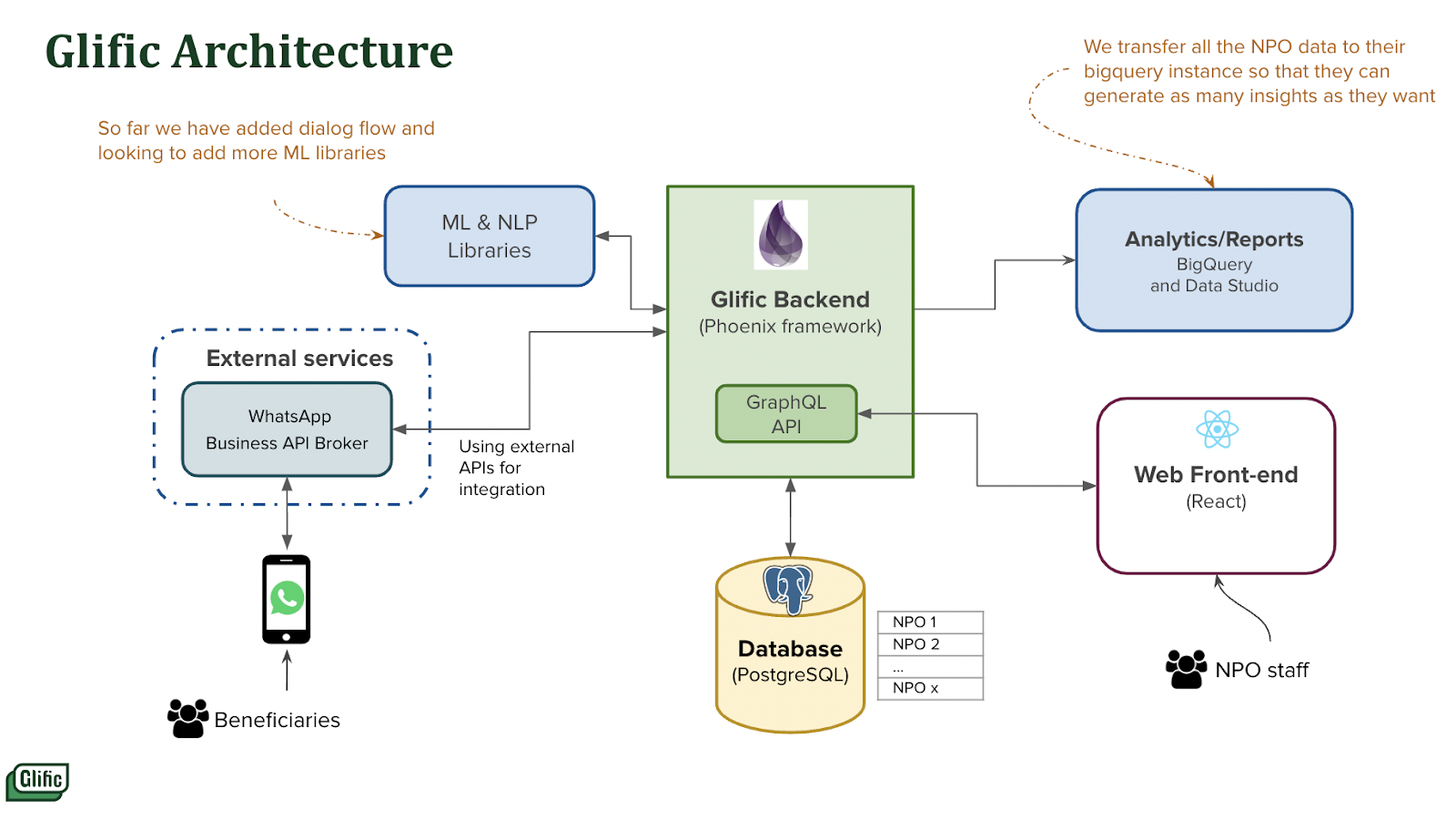
From a social sector organization’s perspective, data is crucial, and at Glific, we want to provide them with useful data and analytics about their chatbot so they can assess how well it is performing. Data analytics is built right into the architecture of Glific where we use a combination of Bigquery and Data Studio.
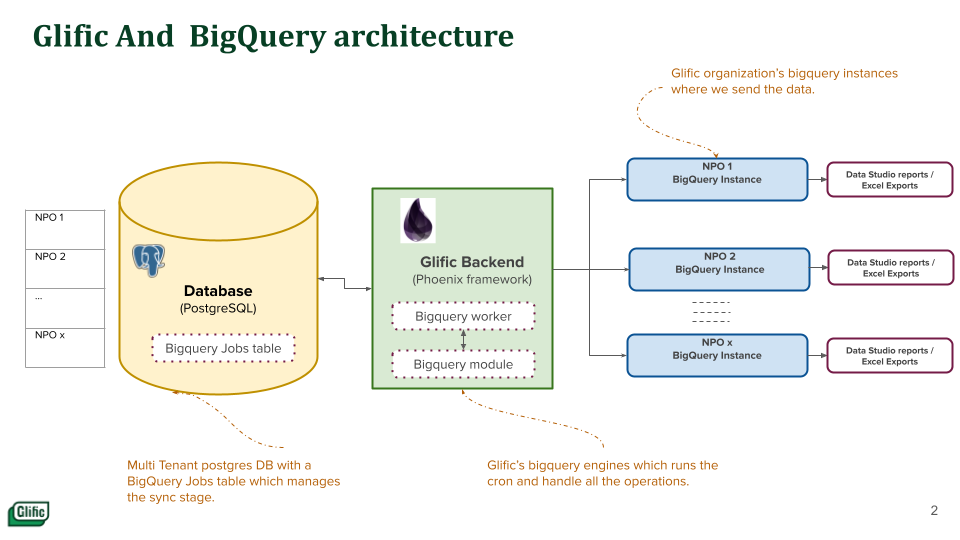
While Bigquery is used to warehouse all the data related to the chatbot which includes contacts, messages, flows, etc. Data Studio is used to generate reports based on the data collected in Bigquery across various tables.
As Glific is a multi-tenant system, where each organization is treated as a tenant and all organizational data is stored in a single database with row-level security and other safeguards. It is simpler to maintain a single version of Glific for all tenants and lowers infrastructure costs overall thanks to multi-tenant architecture.
All of our clients are NGOs, and their most fundamental need is a bespoke reporting dashboard for the data dump (in excel/CSV formats) from Glific of all the information they collected from their chatbot program.
Therefore, instead of offering exports everywhere in Glific, we chose to take all the analytics and reporting part outside Glific through the integration of Bigquery, which makes it much easier to create reports with DataStudio and to export all the data in many formats via UI with little to no SQL expertise.
For us, BigQuery also helps in data security and as a data dump server for organizations.
High-level approach:
Tech Implementation:
Glific and Bigquery data must virtually always be in sync as most NGOs utilize it for real-time data analytics and reporting.
We researched and considered DataPipeline and other methods, however, they were all somewhat complicated and fell short of fulfilling our use case. So we decided to move on with our implementation.
Note: We tried a couple of approaches but I am sharing the final one here which helped us significantly.
Steps:
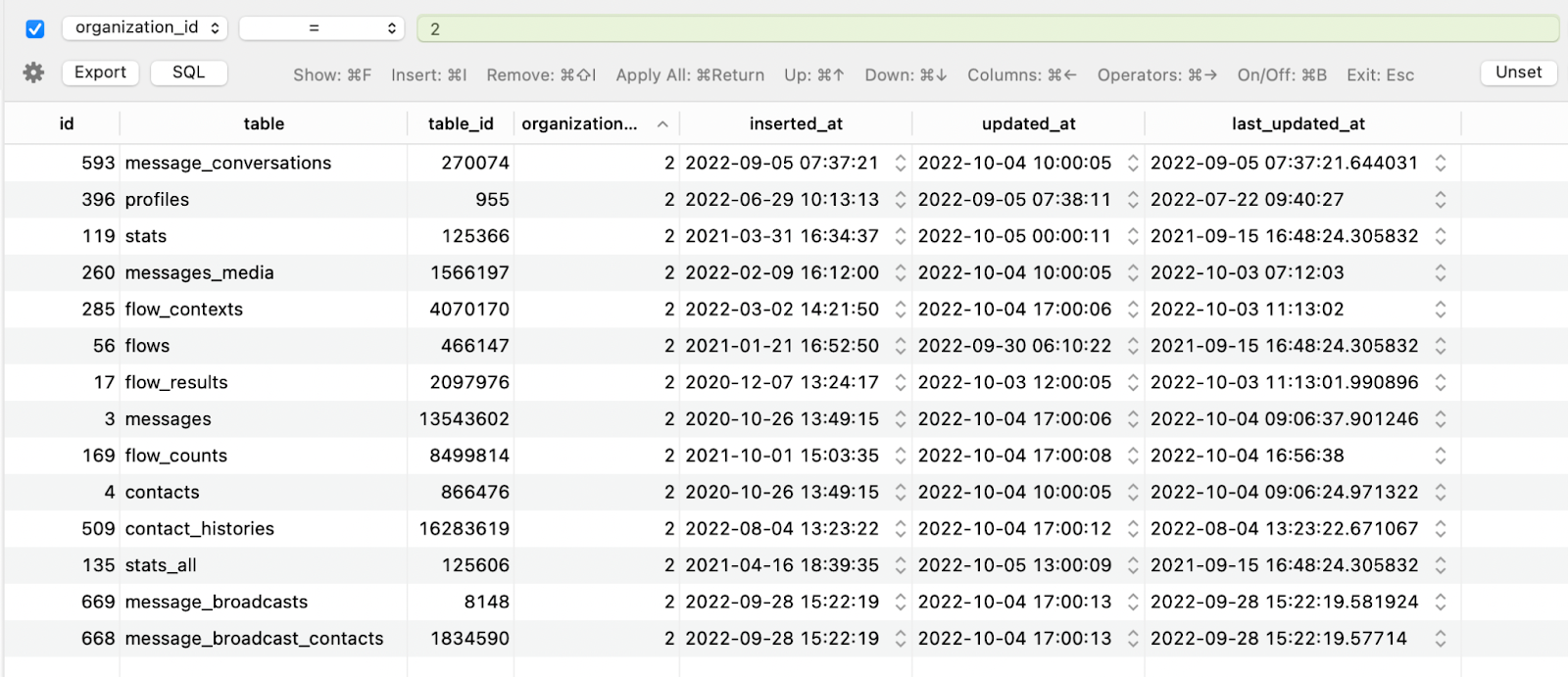
table: Table which we are syncing with the bigquery
table_id: The ID of the row which we have synced with the bigquery
last_updated_at: The timestamp to keep track of the data we updated.
2. A Cron job that runs every minute.
We defined a cron job that runs every minute and checks the process of the Bigquery jobs table. It checks the table one by one, gets the table id field value, and sees if we have more records where the id of that column is greater than the table id in bigger jobs. If we found the records we pushed them to Bigquery and update the latest table id in Bigquery jobs.
Check the following statements which will help to understand what I said in the above statements.
• max_id = Select max(id) from TABLE_NAME where id > bigquery_jobs.table_id
• Update bigquery_jobs set table_id = max_id where table = TABLE_NAMETherefore, when the cron runs again, it will repeat the process and upload the data to Bigquery.
This is a processor-intense task, but Elixir’s lightweight and concurrent behavior really enabled us to accomplish it quickly and effectively.
3. Handle Update records differently.
When we were putting the integration into place, this was the most challenging element, as Bigquery is made to be capable of processing massive volumes of data, assisting several operations, and maintaining the data in the job buffer when we start inserting. Since the job is still in progress, we are unable to update the record. Although the record may be in the job buffer, one can still conduct all selections and other query operations.
We choose to continue putting data into BigQuery and then, later, delete any duplicates.
We added a new field to bigquery jobs called last_updated_at that functions similarly to the table id for updated records.
Thus, the bigquery jobs table will be processed by the minute cron. Check all the records and fetches records that have been updated since the last_updated_at value
Check out the following query for a better understanding.
. last_updated_at = select last_updated_at from bigquery_jobs where table_name = TABLE_NAME
• max_last_updated_at = Select max(updated_at) from TABLE_NAME where updated_at > last_updated_at
• Update bigquery_jobs set last_updated_at = max_last_updated_at where table = TABLE_NAME
Now we just need to insert the records between these two timestamps on bigquery.
4. Delete the old records
As I mentioned earlier, since we are unable to update the BigQuery records, we continuously add new entries while deleting duplicates every 90 minutes. The following query will give you an idea.
DELETE FROM `#{credentials.dataset_id}.#{table}`
WHERE struct(id, updated_at, bq_uuid) IN (
SELECT STRUCT(id, updated_at, bq_uuid) FROM (
SELECT id, updated_at, bq_uuid, ROW_NUMBER() OVER (
PARTITION BY delta.id ORDER BY delta.updated_at DESC
) AS rn
FROM `#{credentials.dataset_id}.#{table}` delta
WHERE updated_at < DATETIME(TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 3 HOUR),
'#{timezone}')) a WHERE a.rn <> 1 ORDER BY id);That’s how we are keeping the sync between the Glific Database and BigQuery. You can check out the full implementation on our Github repo here.
Also let us know if you have a better approach to handle this use case.