May 28, 2020
“TO ERR IS HUMAN” – It is natural for human beings to make mistakes.
Though it sounds ideal, you cannot (or must not) accommodate mistakes when people’s lives may depend on your software. Especially where users are interacting with your app in real-time and your code impacts their lives, errors must be minimized.
How to do that? Automation.
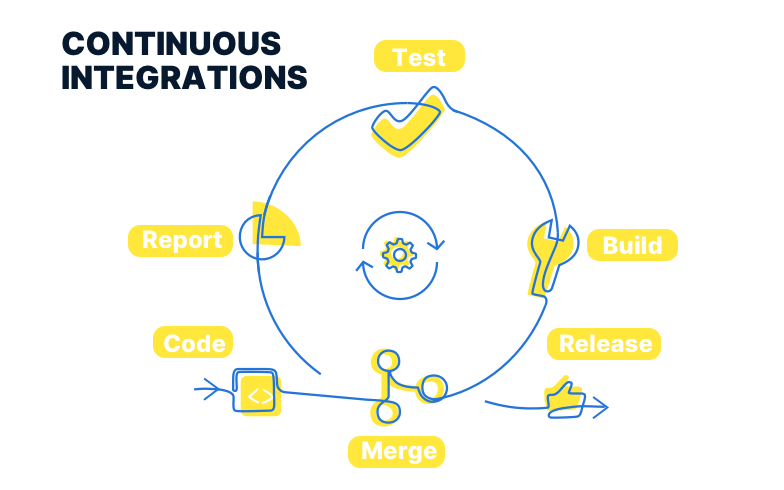
This is where Continuous Integration and Delivery comes into the picture. Taking the example of the open-source project we’re building with Tech4Dev, I’ll share my story on how CI/CD has started to streamline processes and foreseeing errors.
Before diving into tech, let’s take a quick yes/no quiz:
- When you’re leading or in a team of more than 2 people, have you encountered a situation when out-of-blue existing features start to fall apart?
- Are you getting feedback from your client instead of your testing team?
- Is someone from your team assigned to deploy the new version of your software to the server(s) on a regular basis?
If any of your answers are yes, this post is definitely for you and your team. If you answered no to all, either you’re yet to reach these situations or are already doing a great job. In any case, I hope you get more insights into making your processes smoother.
Continuous Integration (CI)
CI brings in automation to test-case execution and verifies the system stability when code changes are pushed by anyone. For this project, we implemented CI using GitHub actions.
Continuous Deployment (CD)
CD, on the other hand, makes the release process smoother and avoids human errors when a new version of your software is going live. We are using the AWS infrastructure for automated releases.
Since the project development hadn’t started yet, I had a lead time to experiment and set up a robust foundation with CI/CD processes.
I spent the experimentation phase researching and applying the concepts on this test repository.
Process for CI
I started out with setting a simple roadmap:
- Configure the application for automated testing. This includes research on how the Phoenix framework supports it.
- Write some example test cases and try running them manually.
- Write test cases for a small use case.
- Continuous Integration – Use GitHub Actions to automate the test cases execution
- Set proper alerts/status to keep track of the state of the application
Getting started in the Phoenix framework was straightforward. The framework supports writing test cases out of the box and has good documentation on it.
Next, to run these test cases using GitHub actions, I created a workflow.yml file that will tell GitHub to execute the test cases every time a developer pushes his/her code changes.
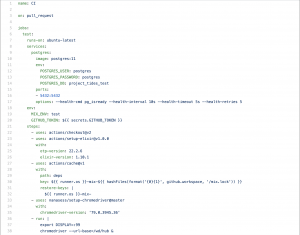
Have a look at ci.yml
Now after some cleanups and fixing errors, I created a feature branch and… Voila! GitHub actions have started triggering on code push.
Process for CD
The roadmap for Continuous Deployment was as follows:
- Dockerize the Phoenix application.
A docker-based setup will help for the easy installation of the application on any machine. Be it an AWS Linux instance or a Windows laptop. If you want to read more dockerizing your app, give this article a read. - Setting up an AWS Elastic Beanstalk environment with support for Docker.
- Setup AWS Code Pipeline that’ll deploy the code from GitHub to our Beanstalk environment whenever the master branch is updated.
For dockerizing the app, I created a Dockerfile that defines the platform dependencies for the project. When you run the docker-compose run, it creates a container with all the installations mentioned in the Dockerfile.

Have a look at the Dockerfile
Next, the Dockerrun.json file needs to be created that will be executed to deploy the docker image to our Elastic Beanstalk setup.

Finally, setting up AWS CodePipeline. Here are the configurations I used:
| Source: | GitHub repository for the project. Webhook for the master branch. |
| Build: | AWS CodeBuild that installs the application on an Elastic Container Registry (ECR). |
| Deploy: | Pushing compiled code from ECR to the dockerized Beanstalk environment. |
Whenever the master branch was updated, AWS triggers the CodePipeline.
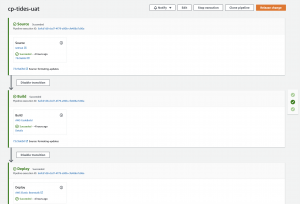
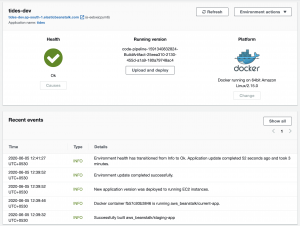
Once CodePipeline execution is complete, we can do a quick health check of our Beanstalk environment
Final thoughts
Having the automation in place, clearly, the time-to-market is reduced and the team will ship quality code. This is happening as the errors are being detected early on.
On top of that, setting up the CI/CD early in the process ensures the following things:
- It’ll be an integral part of the Software Development Life Cycle setting up the right from the beginning.
- Implementing it later comes with a high effort and cost is always a pain.
- With proper test coverage, the foundation will be strong. Minimizing rework.
- When a new developer joins in, they are more likely to code buggy pieces due to lesser domain knowledge. Having test cases will ensure that the system remains stable at all times and we detect these breaking changes early in the process.
To know more about the project, check out the following stories: