September 10, 2020
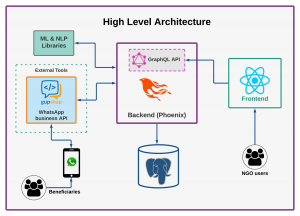
The Glific project is being built by a distributed team, working across timezones. In addition to that, we have sub-teams for frontend and backend applications. This results in short release cycles, where we fix issues and release them quickly. To allow for quick integration and assessment of the work, the need for Continuous Integration and deployment was felt. That ensured the UAT was always up to date with the latest code for the product development team to look at.
In Glific, we decided to deploy and avail the changes at the staging site as soon as it got merged, and we needed the CD implementation.
We used the following AWS infrastructure to achieve the target goal. We are not going in the technical implementation but on the overview of how we have set it up currently, and why we went with this setup.
Tech stack in Glific:
We had the following tech stack and we were thinking about the possibilities of different infrastructures.
- React JS for frontend application.
- Phoenix/Elixir for backend API.
- Postgres database.
“How to eat an elephant? Cut it down into pieces and take one piece at a time. Have that resilience to make sure you finish that elephant.”
Following the same philosophy, we divided the whole process into two different phases
Phase 1: Dockerizing both the applications.
Phase 2: Designing and implementing a CD compatible infrastructure.
Phase 1: Dockerizing the applications
Both applications are fully dockerized. We can create the latest docker image and run it in any stack compatible with docker.
Why did we go with a docker based setup?
We researched and found there are lots of advantages of going with a dockerized setup.
Compatibility and maintainability: We found it most compatible as It provides a consistent environment for CD. After the initial setup effort, it has low maintenance cost compared to non containerized applications.
Rapid development: It has comparatively low deployment time as we can easily put a new version of the software into production rapidly and if anything goes, we can quickly roll back to a previous version.
Isolation: It ensures that each container has its resources and runs a separate application that is isolated from other containers. You can have various containers for separate applications running completely different stacks.
Check out how I’ve implemented it in my another blog on Continuous integration & deployment for open source project.
Phase 2: Designing and implementing a CD compatible infrastructure.
As we dockerized both applications in phase 1, it was the time to get benefited.
The tech stack we used to design our infrastructure are:
- AWS ECS fargate for deploying containerized applications.
- AWS ECR for storing docker images.
- AWS ELB for handling network traffic.
- AWS CodePipeline for implementing CD.
- RDS for the database.
Why Amazon Elastic Container Service (Amazon ECS)?
Amazon ECS is a highly scalable and high-performance container orchestration (automated configuration, management, and coordination of computer systems) service meant to support Docker-based containerized applications to run and scale as needed. You don’t need to manage the infrastructure or other operations such as tasks, services, auto-scaling, etc.
Why Fargate?
AWS Fargate is a serverless launch type for Amazon ECS that allows you to run containers. You don’t have to manage servers or clusters, provision, configurations, and scaling clusters to run containers.
ECS gives two choices, either we go with EC2 or Fargate. We found the following reason to go with Fargate.
Resource utilization: Most of the time, the EC2 instance doesn’t utilize the resources correctly while If you are using Fargate, you don’t need to think about managing those resources.
Automation: It reduces manual intervention, Fargate task configurations (definition) seamlessly meets the application’s computing requirements.
Autoscaling capability: If your application needs more resources and you have enabled this, you don’t need to worry about how you will scale it further whenever required.
Pricing: Fargate Launch Type, billing is based on CPU or memory requirements per second. You only have to pay for what your task uses, no need to pay for extra for EC2 instances that go unused.
Deploying with ECS Fargate
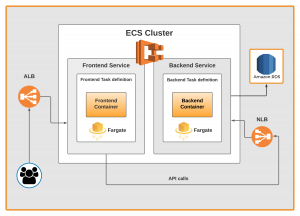
To deploy our Glific applications on ECS, we need the following 4 items set up.
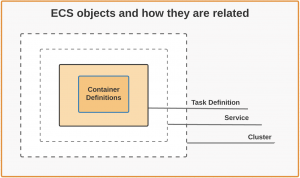
- Container Definition: It includes the configurations of a container that includes where we are getting docker image, which port we are exposing, environmental variables, hard/soft CPU limits which Task definition will use to run the container.
- Task Definition: This contains the definition that describes how a docker container should launch. It contains settings like CPU shares, memory requirements, etc.
- Service: It enables us to run and maintain a specified number of instances of a task definition simultaneously in an Amazon ECS cluster. ie. It helps us run single or multiple containers all using the same Task Definition.
- Cluster: It is a logical group of container instances that ECS can use for deploying Docker containers.
Here is how it looks when we successfully deployed our applications on ECS.
Why AWS ECR?
Amazon Elastic Container Registry (ECR), which is a private Docker Registry managed by AWS. Though we can use the docker hub repository, seeing compatibility with Fargate and CodePipeline, I preferred to use ECR over the docker hub to store docker images we are building using the AWS CodePipeline.
Elastic Load balancer (ELB) for external routing.
We are using AWS Elastic load balancer for external routing. As we have two different applications, we used different Load balancers for each application.
- ALB (Application Load Balancer) for handling frontend traffic.
- NLB (Network Load Balancer) for handling backend API traffic.
Why we are using NLB (Network Load Balancer) for the backend application?
The glific backend is using socket requests for live chat which uses custom TCP and ALB only provides HTTP/HTTPS. To make the socket connection work, we needed an NLB that supports custom TCP.
RDS for the database
In Glific, we are using the Postgres database. Seeing the advantages, RDS is a good choice for our application. It provides high availability, scalability, and performance. It also provides the Backup mechanism whether that is automated or Point-in-Time snapshots which the user initiates.
AWS codepipeline for implementing CD
AWS CodePipeline is an Amazon Web Services for CI/CD of applications hosted on various AWS platforms. It automates the software deployment process allowing a developer to quickly model, visualize, and deliver code for new features and updates.
Our CodePipeline is consisting of three different stages:
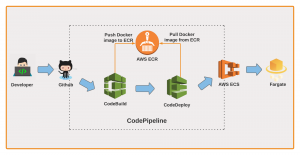
Source: We are using GitHub as a source code repository. This step checks for any changes on a specific branch (configured while creating this step) and pulls the code changes.
Build: This stage uses the codebase available after running step 1, builds the docker image, and pushes it to the ECR.
Deploy: This stage is responsible to deploy the latest docker image to AWS ECS (Fargate) service.
It creates a replica of the old ECS task and runs it parallel with the old one. If the deployment fails due to any reason, it stops the new task but the old task remains up.
If everything goes well, it triggers a health check on a new task, and on success, it stops the old task.
The benefit of using an AWS CodePipeline for an AWS ECS service is that the ECS service continues to run while a new Docker image is built and deployed. So the user will not be facing any downtime in between.
Conclusion:
- Containers are becoming standard of the industry to deploy and run applications. We are successfully able to deploy the whole Glific solution with the CD in place.
- We also went through the serverless deployment of applications as Amazon Fargate allowed us to specify our service requirements without going deeper into managing EC2 infrastructure.
- The CodePipeline uses the CodeBuild which builds and pushes the docker image to ECR which ECS is using for task deployment.
- Step 3 of CodePipeline deploys the application to ECS by using ECS task definition that too without any downtime for the user.
I’ll be posting the blog consisting of a detailed step by step deployment guideline. Stay in touch for the updates.